|
1 | 1 |
|
2 | | -# AsyncFlow — Event-Loop Aware Simulator for Async Distributed Systems |
| 2 | +# AsyncFlow: Scenario-Driven Simulator for Async Systems |
3 | 3 |
|
4 | 4 | Created and maintained by @GioeleB00. |
5 | 5 |
|
6 | 6 | [](https://pypi.org/project/asyncflow-sim/) |
7 | 7 | [](https://pypi.org/project/asyncflow-sim/) |
8 | 8 | [](LICENSE) |
9 | | -[](#) |
| 9 | +[](https://codecov.io/gh/AsyncFlow-Sim/AsyncFlow) |
10 | 10 | [](https://github.com/astral-sh/ruff) |
11 | 11 | [](https://mypy-lang.org/) |
12 | 12 | [](https://docs.pytest.org/) |
13 | 13 | [](https://simpy.readthedocs.io/) |
14 | 14 |
|
15 | 15 | ----- |
16 | 16 |
|
17 | | -AsyncFlow is a discrete-event simulator for modeling and analyzing the performance of asynchronous, distributed backend systems built with SimPy. You describe your system's topology—its servers, network links, and load balancers—and AsyncFlow simulates the entire lifecycle of requests as they move through it. |
| 17 | +**AsyncFlow** is a scenario-driven simulator for **asynchronous distributed backends**. |
| 18 | +You don’t “predict the Internet” — you **declare scenarios** (network RTT + jitter, resource caps, failure events) and AsyncFlow shows the operational impact: concurrency, queue growth, socket/RAM pressure, latency distributions. This means you can evaluate architectures before implementation: test scaling strategies, network assumptions, or failure modes without writing production code. |
18 | 19 |
|
19 | | -It provides a **digital twin** of your service, modeling not just the high-level architecture but also the low-level behavior of each server's **event loop**, including explicit **CPU work**, **RAM residency**, and **I/O waits**. This allows you to run realistic "what-if" scenarios that behave like production systems rather than toy benchmarks. |
| 20 | +At its core, AsyncFlow is **event-loop aware**: |
| 21 | + |
| 22 | +* **CPU work** blocks the loop, |
| 23 | +* **RAM residency** ties up memory until release, |
| 24 | +* **I/O waits** free the loop just like in real async frameworks. |
| 25 | + |
| 26 | +With the new **event injection engine**, you can explore *what-if* dynamics: network spikes, server outages, degraded links, all under your control. |
| 27 | + |
| 28 | +--- |
20 | 29 |
|
21 | 30 | ### What Problem Does It Solve? |
22 | 31 |
|
23 | | -Modern async stacks like FastAPI are incredibly performant, but predicting their behavior under real-world load is difficult. Capacity planning often relies on guesswork, expensive cloud-based load tests, or discovering bottlenecks only after a production failure. AsyncFlow is designed to replace that uncertainty with **data-driven forecasting**, allowing you to understand how your system will perform before you deploy a single line of code. |
| 32 | +Predicting how an async system will behave under real-world load is notoriously hard. Teams often rely on rough guesses, over-provisioning, or painful production incidents. **AsyncFlow replaces guesswork with scenario-driven simulations**: you declare the conditions (network RTT, jitter, resource limits, injected failures) and observe the consequences on latency, throughput, and resource pressure. |
| 33 | + |
| 34 | +--- |
| 35 | + |
| 36 | +### Why Scenario-Driven? *Design Before You Code* |
| 37 | + |
| 38 | +AsyncFlow doesn’t need your backend to exist. |
| 39 | +You can model your architecture with YAML or Python, run simulations, and explore bottlenecks **before writing production code**. |
| 40 | +This scenario-driven approach lets you stress-test scaling strategies, network assumptions, and failure modes safely and repeatably. |
| 41 | + |
| 42 | +--- |
| 43 | + |
| 44 | +### How Does It Work? |
24 | 45 |
|
25 | | -### How Does It Work? An Example Topology |
| 46 | +AsyncFlow represents your system as a **directed graph of components**, for example: clients, load balancers, servers—connected by network edges with configurable latency models. Each server is **event-loop aware**: CPU work blocks, RAM stays allocated, and I/O yields the loop, just like real async frameworks. You can define topologies via **YAML** or a **Pythonic builder**. |
26 | 47 |
|
27 | | -AsyncFlow models your system as a directed graph of interconnected components. A typical setup might look like this: |
| 48 | +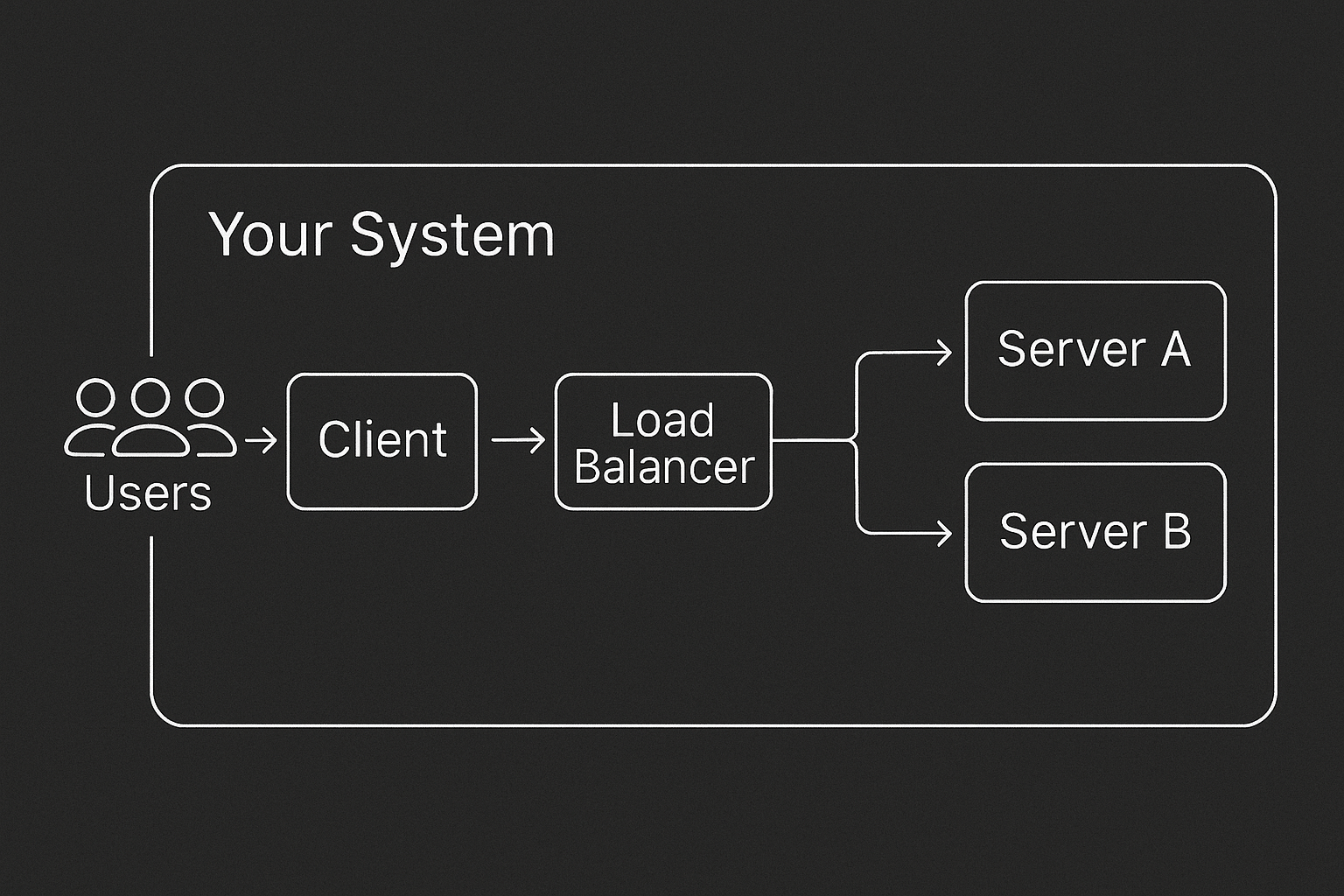 |
28 | 49 |
|
29 | | - |
| 50 | +Run the simulation and inspect the outputs: |
| 51 | + |
| 52 | +<p> |
| 53 | + <a href="https://raw.githubusercontent.com/AsyncFlow-Sim/AsyncFlow/main/readme_img/lb_dashboard.png"> |
| 54 | + <img src="https://raw.githubusercontent.com/AsyncFlow-Sim/AsyncFlow/main/readme_img/lb_dashboard.png" alt="Latency + Throughput Dashboard" width="300"> |
| 55 | + </a> |
| 56 | + <a href="https://raw.githubusercontent.com/AsyncFlow-Sim/AsyncFlow/main/readme_img/lb_server_srv-1_metrics.png"> |
| 57 | + <img src="https://raw.githubusercontent.com/AsyncFlow-Sim/AsyncFlow/main/readme_img/lb_server_srv-1_metrics.png" alt="Server 1 Metrics" width="300"> |
| 58 | + </a> |
| 59 | + <a href="https://raw.githubusercontent.com/AsyncFlow-Sim/AsyncFlow/main/readme_img/lb_server_srv-2_metrics.png"> |
| 60 | + <img src="https://raw.githubusercontent.com/AsyncFlow-Sim/AsyncFlow/main/readme_img/lb_server_srv-2_metrics.png" alt="Server 2 Metrics" width="300"> |
| 61 | + </a> |
| 62 | +</p> |
| 63 | + |
| 64 | + |
| 65 | +--- |
30 | 66 |
|
31 | 67 | ### What Questions Can It Answer? |
32 | 68 |
|
33 | | -By running simulations on your defined topology, you can get quantitative answers to critical engineering questions, such as: |
| 69 | +With scenario simulations, AsyncFlow helps answer questions such as: |
| 70 | + |
| 71 | +* How does **p95 latency** shift if active users double? |
| 72 | +* What happens when a **client–server edge** suffers a 20 ms spike for 60 seconds? |
| 73 | +* Will a given endpoint pipeline — CPU parse → RAM allocation → DB I/O — still meet its **SLA at 40 RPS**? |
| 74 | +* How many sockets and how much RAM will a load balancer need under peak conditions? |
34 | 75 |
|
35 | | - * How does **p95 latency** change if active users increase from 100 to 200? |
36 | | - * What is the impact on the system if the **client-to-server network latency** increases by 3ms? |
37 | | - * Will a specific API endpoint—with a pipeline of parsing, RAM allocation, and database I/O—hold its **SLA at a load of 40 requests per second**? |
38 | 76 | --- |
39 | 77 |
|
40 | 78 | ## Installation |
@@ -167,7 +205,7 @@ You’ll get latency stats in the terminal and a PNG with four charts (latency d |
167 | 205 |
|
168 | 206 | **Want more?** |
169 | 207 |
|
170 | | -For ready-to-run scenarios—including examples using the Pythonic builder and multi-server topologies—check out the `examples/` directory in the repository. |
| 208 | +For ready-to-run scenarios including examples using the Pythonic builder and multi-server topologies, check out the `examples/` directory in the repository. |
171 | 209 |
|
172 | 210 | ## Development |
173 | 211 |
|
@@ -279,97 +317,28 @@ bash scripts/run_sys_tests.sh |
279 | 317 |
|
280 | 318 | Executes **pytest** with a terminal coverage summary (no XML, no slowest list). |
281 | 319 |
|
| 320 | +## Current Limitations (v0.1.1) |
282 | 321 |
|
| 322 | +AsyncFlow is still in alpha. The current release has some known limitations that are already on the project roadmap: |
283 | 323 |
|
284 | | -## What AsyncFlow Models (v0.1) |
285 | | - |
286 | | -AsyncFlow provides a detailed simulation of your backend system. Here is a high-level overview of the core components it models. For a deeper technical dive into the implementation and design rationale, follow the links to the internal documentation. |
287 | | - |
288 | | -* **Async Event Loop:** Simulates a single-threaded, non-blocking event loop per server. **CPU steps** block the loop, while **I/O steps** are non-blocking, accurately modeling `asyncio` behavior. |
289 | | - * *(Deep Dive: `docs/internals/runtime-and-resources.md`)* |
290 | | - |
291 | | -* **System Resources:** Models finite server resources, including **CPU cores** and **RAM (MB)**. Requests must acquire these resources, creating natural back-pressure and contention when the system is under load. |
292 | | - * *(Deep Dive: `docs/internals/runtime-and-resources.md`)* |
293 | | - |
294 | | -* **Endpoints & Request Lifecycles:** Models server endpoints as a linear sequence of **steps**. Each step is a distinct operation, such as `cpu_bound_operation`, `io_wait`, or `ram` allocation. |
295 | | - * *(Schema Definition: `docs/internals/simulation-input.md`)* |
296 | | - |
297 | | -* **Network Edges:** Simulates the connections between system components. Each edge has a configurable **latency** (drawn from a probability distribution) and an optional **dropout rate** to model packet loss. |
298 | | - * *(Schema Definition: `docs/internals/simulation-input.md` | Runtime Behavior: `docs/internals/runtime-and-resources.md`)* |
299 | | - |
300 | | -* **Stochastic Workload:** Generates user traffic based on a two-stage sampling model, combining the number of active users and their request rate per minute to produce a realistic, fluctuating load (RPS) on the system. |
301 | | - * *(Modeling Details with mathematical explanation and clear assumptions: `docs/internals/requests-generator.md`)* |
302 | | - |
303 | | -* **Metrics & Outputs:** Collects two types of data: **time-series metrics** (e.g., `ready_queue_len`, `ram_in_use`) and **event-based data** (`RqsClock`). This raw data is used to calculate final KPIs like **p95/p99 latency** and **throughput**. |
304 | | - * *(Metric Reference: `docs/internals/metrics`)* |
305 | | - |
306 | | -## Current Limitations (v0.1) |
307 | | - |
308 | | -* Network realism: base latency + optional drops (no bandwidth/payload/TCP yet). |
309 | | -* Single event loop per server: no multi-process/multi-node servers yet. |
310 | | -* Linear endpoint flows: no branching/fan-out within an endpoint. |
311 | | -* No thread-level concurrency; modeling OS threads and scheduler/context switching is out of scope.” |
312 | | -* Stationary workload: no diurnal patterns or feedback/backpressure. |
313 | | -* Sampling cadence: very short spikes can be missed if `sample_period_s` is large. |
314 | | - |
315 | | - |
316 | | -## Roadmap (Order is not indicative of priority) |
317 | | - |
318 | | -This roadmap outlines the key development areas to transform AsyncFlow into a comprehensive framework for statistical analysis and resilience modeling of distributed systems. |
319 | | - |
320 | | -### 1. Monte Carlo Simulation Engine |
321 | | - |
322 | | -**Why:** To overcome the limitations of a single simulation run and obtain statistically robust results. This transforms the simulator from an "intuition" tool into an engineering tool for data-driven decisions with confidence intervals. |
323 | | - |
324 | | -* **Independent Replications:** Run the same simulation N times with different random seeds to sample the space of possible outcomes. |
325 | | -* **Warm-up Period Management:** Introduce a "warm-up" period to be discarded from the analysis, ensuring that metrics are calculated only on the steady-state portion of the simulation. |
326 | | -* **Ensemble Aggregation:** Calculate means, standard deviations, and confidence intervals for aggregated metrics (latency, throughput) across all replications. |
327 | | -* **Confidence Bands:** Visualize time-series data (e.g., queue lengths) with confidence bands to show variability over time. |
328 | | - |
329 | | -### 2. Realistic Service Times (Stochastic Service Times) |
330 | | - |
331 | | -**Why:** Constant service times underestimate tail latencies (p95/p99), which are almost always driven by "slow" requests. Modeling this variability is crucial for a realistic analysis of bottlenecks. |
332 | | - |
333 | | -* **Distributions for Steps:** Allow parameters like `cpu_time` and `io_waiting_time` in an `EndpointStep` to be sampled from statistical distributions (e.g., Lognormal, Gamma, Weibull) instead of being fixed values. |
334 | | -* **Per-Request Sampling:** Each request will sample its own service times independently, simulating the natural variability of a real-world system. |
335 | | - |
336 | | -### 3. Component Library Expansion |
337 | | - |
338 | | -**Why:** To increase the variety and realism of the architectures that can be modeled. |
339 | | - |
340 | | -* **New System Nodes:** |
341 | | - * `CacheRuntime`: To model caching layers (e.g., Redis) with hit/miss logic, TTL, and warm-up behavior. |
342 | | - * `APIGatewayRuntime`: To simulate API Gateways with features like rate-limiting and authentication caching. |
343 | | - * `DBRuntime`: A more advanced model for databases featuring connection pool contention and row-level locking. |
344 | | -* **New Load Balancer Algorithms:** Add more advanced routing strategies (e.g., Weighted Round Robin, Least Response Time). |
345 | | - |
346 | | -### 4. Fault and Event Injection |
347 | | - |
348 | | -**Why:** To test the resilience and behavior of the system under non-ideal conditions, a fundamental use case for Site Reliability Engineering (SRE). |
349 | | - |
350 | | -* **API for Scheduled Events:** Introduce a system to schedule events at specific simulation times, such as: |
351 | | - * **Node Down/Up:** Turn a server off and on to test the load balancer's failover logic. |
352 | | - * **Degraded Edge:** Drastically increase the latency or drop rate of a network link. |
353 | | - * **Error Bursts:** Simulate a temporary increase in the rate of application errors. |
354 | | - |
355 | | -### 5. Advanced Network Modeling |
| 324 | +* **Network model** — only base latency + jitter/spikes. |
| 325 | + Bandwidth, queuing, and protocol-level details (HTTP/2 streams, QUIC, TLS handshakes) are not yet modeled. |
356 | 326 |
|
357 | | -**Why:** To more faithfully model network-related bottlenecks that are not solely dependent on latency. |
| 327 | +* **Server model** — single event loop per server. |
| 328 | + Multi-process or multi-threaded execution is not yet supported. |
358 | 329 |
|
359 | | -* **Bandwidth and Payload Size:** Introduce the concepts of link bandwidth and request/response size to simulate delays caused by data transfer. |
360 | | -* **Retries and Timeouts:** Model retry and timeout logic at the client or internal service level. |
| 330 | +* **Endpoint flows** — endpoints are linear pipelines. |
| 331 | + Branching/fan-out (e.g. service calls to DB + cache) will be added in future versions. |
361 | 332 |
|
362 | | -### 6. Complex Endpoint Flows |
| 333 | +* **Workload generation** — stationary workloads only. |
| 334 | + No support yet for diurnal patterns, feedback loops, or adaptive backpressure. |
363 | 335 |
|
364 | | -**Why:** To model more realistic business logic that does not follow a linear path. |
| 336 | +* **Overload policies** — no explicit handling of overload conditions. |
| 337 | + Queue caps, deadlines, timeouts, rate limiting, and circuit breakers are not yet implemented. |
365 | 338 |
|
366 | | -* **Conditional Branching:** Introduce the ability to have conditional steps within an endpoint (e.g., a different path for a cache hit vs. a cache miss). |
367 | | -* **Fan-out / Fan-in:** Model scenarios where a service calls multiple downstream services in parallel and waits for their responses. |
| 339 | +* **Sampling cadence** — very short events may be missed if the `sample_period_s` is too large. |
368 | 340 |
|
369 | | -### 7. Backpressure and Autoscaling |
370 | 341 |
|
371 | | -**Why:** To simulate the behavior of modern, adaptive systems that react to load. |
372 | 342 |
|
373 | | -* **Dynamic Rate Limiting:** Introduce backpressure mechanisms where services slow down the acceptance of new requests if their internal queues exceed a certain threshold. |
374 | | -* **Autoscaling Policies:** Model simple Horizontal Pod Autoscaler (HPA) policies where the number of server replicas increases or decreases based on metrics like CPU utilization or queue length. |
| 343 | +📌 See the [ROADMAP](./ROADMAP.md) for planned features and upcoming milestones. |
375 | 344 |
|
0 commit comments